What is Interpretability?
This post was coauthored by Stanislav Böhm and Tomáš Gavenčiak, and cross posted to the Alignment Forum
In this post we lay out some ideas around framing interpretability research which we have found quite useful. Our framing is goal-oriented, which we believe is important for making sure interpretability research is meaningful. We also go over a variety of dimensions which we think are useful to consider when thinking about interpretability research. We wanted to have a shared vocabulary when talking about this kind of research, and found that these ideas helped us communicate effectively.
One of our motivations for having these thoughts and discussions is so we can understand the relevance of interpretability to alignment, and to help us think about which categories or dimensions of interpretability research are important for alignment of strong AI. In a coming post we discuss interpretability and alignment, using the ideas from this post and other previous writing on the subject.
Interpretability, transparency, explainability?
A quick note on terminology. Many terms are used to mean many similar things in the interpretability research literature. We think of Interpretability as the broadest possible category, which is why it can be hard to define and operationalise. Two specific terms are used with frequency apart from interpretability - explainability and transparency - and following the definitions in The Mythos Of Model Interpretability (summarised in more detail in the appendix), we’ll use them as follows:
- Explainability is usually a post-hoc action, where we want to understand and explain why a model made a specific prediction (or enacted certain behaviour) after the fact.
- Transparency is normally seen as a more intrinsic property of a model, and is about understanding it’s internal workings and mechanisms. This is often a harder property to achieve. This can often mean a human would be able to “Run an approximation of the algorithm in their head”.
Dimensions for interpretability
We found two dimensions most useful to consider when thinking about interpretability. The first dimension (Goals) is concerned with which goals interpretability research aims to fulfil. The second (Enabling Humans) refers to the idea that interpretability is human-centred, and we feel that interpretability methods normally must have a human involved in interpreting the model for them to be meaningful. We could also consider agents acting on behalf of humans (i.e. in amplification or recursive reward modelling). These aren’t the only axes on which to consider interpretability research (see Other Dimensions), but they are the two we felt were the most useful.
Goals
Possibly the most important dimension to consider is the Goals of interpretability methods. We describe five generic goals (not specific to certain domains). We found that this helps us the most when thinking about what kinds of interpretability methods we should pursue developing and what a specific interpretability method is hoping to achieve. This is descriptive, in that these are (generic) goals researchers have put forward for using interpretability methods, or that interpretability methods have been used to achieve. There’s overlap between these goals, and especially the first three are interrelated, as are the last two.
The goals are:
- Predicting behaviour - This is about being able to predict a model’s behaviour in novel scenarios. This normally will be without having a full formal definition of the scenario (otherwise we should just run it through the model and see what it does). We might care about predicting large classes of behaviour (“The model never acts against human interest”) which is overlapping with the Assurance of properties goal below; we might also care about more specific classes of behaviour (“Will the agent smash the red vase in this gridworld?”).
- Some current methods which might help with this are Counterfactual States for Atari Agents via Generative Deep Learning and Finding and Visualizing Weaknesses of Deep Reinforcement Learning Agents, as they both visualise what states would produce certain behaviours, and hence enable us to predict behaviours in these states.
- One way in which this goal can be validated is to test whether it enables users to construct inputs which produce a certain behaviour, rather than predicting the input given the behaviour. This would have to be done without access to the model (otherwise you could just optimise for that behaviour). The two methods above are examples of this kind of approach: Having seen several visualisations of counterfactual states, you could be able to produce counterfactual states on your own without the method, which demonstrates you’ve gained some understanding of the model enough to predict it’s behaviour.
- Assurance of properties - This is related to the Predicting Behaviour goal, but where the goal is to give broader assurances that are better described as properties rather than specific behavioural predictions. In the strongest form, this might take the form of formal verification, but in weaker forms we might be satisfied with visualisations or explanations of behaviour which imply that the model has a certain property.
- Understanding Black-box Predictions via Influence Functions and Estimating Training Data Influence by Tracking Gradient Descent are both methods designed to find training data which is influential for specific model decisions. If a model’s influential training points for a specific action are unrelated to this action, we might suppose that the model has learned spurious correlations rather than a robust approach. These methods can hence give us a small amount of assurance that the model is reasoning correctly about it’s inputs.
- Visualising adversarial examples might give us some assurance of the robustness (or not) of the network to adversarial attacks.
- We could also consider value learning as an interpretability method. In the case of perfect IRL, we can find the revealed preferences of an agent, and having these preferences would allow you to examine some properties of the agent. This would also help with Predicting Behaviour.
- Persuasion of properties - This is similar to the Assurance of properties goal, but with the difference that the aim is purely persuasion of a person, rather than a truthful representation of the model’s properties. Often interpretability methods might be used to convince a non-technical person (perhaps an auditor or a companies machine learning models) that the model has certain properties. This goal can often be problematic, as the incentives come apart from truthfully presenting the behaviour or properties of the model. That is, we could create methods that produce pretty interesting visualisations which seem to show the model is doing the right thing, when the visualisations aren’t actually dependent on the model’s parameters.
- Sanity Checks for Saliency Maps and The (Un)reliability of Saliency methods both seem to point at the possibility that saliency maps are doing this implicitly. Obviously no researcher is explicitly thinking “Let’s find the prettiest picture to convince people or some interesting property”, but without better forms of validation this seems like it could happen by accident for some methods. This was one of our motivations for coming up with a goal-oriented framing in the first place
- Note that we’re not saying this a goal one should aim for, and it’s rarely if ever explicitly mentioned as a goal in literature; however, it likely to have been (at least implicitly) optimised for in certain methods, as the above bullet point alludes to.
- Improving model performance - Many methods are designed to give us understanding which we can use to improve the performance of the model. We might find weaknesses in how the model currently performs, or unbalanced training data, which we can use to improve the model’s performance.
- For example, saliency maps (Visualizing and Understanding Atari Agents, Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization, many others) tell us what the model is attending to in the input, which can tell us whether it’s learning the correct signals and information to attend to. This information might help us improve the model behaviour.
- When trying to improve the robustness of our models, especially by adversarial training, we might use interpretability methods to find uninterpretable or seemingly un-robust behaviours, and bias our adversarial training towards these behaviours. If the behaviours are reliant on spurious correlations, then we can improve the robustness of our model by training on examples where these correlations break down, and if they in fact are robust, then we may have learned something new about the environment or task which we didn’t realise beforehand.
- Debugging model - Similar to the Improving model performance, and especially in deep learning, this is about finding incorrect model behaviour and fixing it.
- To clarify the difference from Improving model performance, we might say a model is implemented and executing correctly if it’s implementation is fully faithful to the conception in your head, or to some pseudocode, mathematical formula or design document. In this case, we might use interpretability to Improve model performance by giving us insights into how it behaves.
- However, we might say a model is implemented (and hence executing) incorrectly if it’s implementation is unfaithful to the pseudocode, mathematical formulation or design document, most likely due to an error in implementation, or a possibly hidden assumption being violated in the training process. For example, we might assume that all the training data is labelled correctly, but it might not be, and we may be able to find this using interpretability methods. This would fall under Debugging models rather than Improving model performance.
- This might take the form of an interactive debugger or some logging view such as tensorboard, or visualisations of the flow of gradients through the network, to make sure they’re flowing the way you expect.
A key caveat is that many methods might not target a specific goal in the above list, but instead aim to produce in the end-user of the interpretability method some Generic Understanding or a Gearful Model of the object being interpreted. This understanding could then serve in the fulfilment of a variety of goals, such as aiding the user in predicting behaviour, or understanding why the model fails and hence improving its performance. A key example of these kinds of Generic Understanding methods are the series of methods based on Feature Visualisation, especially the Activation Atlas. The Activation Atlas paper is a good example of a method giving Generic Understanding which is then cashed out in the ability to produce adversarial examples aimed at specific things using only overlapping natural images, which is a kind of Predicting Behaviour.
We want to stress, however, that validating whether a interpretability method produces genuine understanding seems very difficult (or perhaps impossible) to do without seeing whether the understanding can be cashed out to achieve one of the goals above. The aim when trying to produce understanding should not be for the user to just feel like they understand the method, but rather for the user’s understanding to enable them to better achieve one of the goals above. If a method produces some fuzzy feeling of understanding but doesn’t seem useful for any downstream task, then it’s worth considering what it’s useful for.
Enabling Humans
The second dimension, Enabling Humans, is about whether the method enables a human to achieve one of the goals above, as opposed to achieving the goal directly. That is, there are many methods or algorithms in machine learning which Improve model performance, such as the Adam optimiser or adding more layers to your neural network. These techniques are obviously not interpretability techniques, but it’s useful to think about the difference between them and a technique we would call interpretability which does enable an improvement in model performance.
We think the key difference is the existence of a human in a chain between interpretability method and in this case Improvement of model performance. An interpretability method will Enable Humans to achieve the goals above. For a method such as automatic verification (which could be considered interpretability) the verifier is doing the vast majority of the work, but the human still needs to decide what to verify, i.e. they need to ask the right questions. On the other hand, methods such as feature visualisation and saliency maps only provide some visualisation of the model behaviour or internals, and hence still require human effort to achieve one of the goals above.
For some of the goals above this is basically guaranteed: When trying to gain Assurance of Properties, we’re the human in the loop, and the method could give us these assurances or enable us to find them for ourselves. However as mentioned above, for Improving model performance the distinction becomes more necessary.
This dimension is more difficult to reason about than the Goals dimension, and is hence less fleshed out. However, we think it’s just as important to consider what the role of the human is in an interpretability method’s use.
A Map of Methods
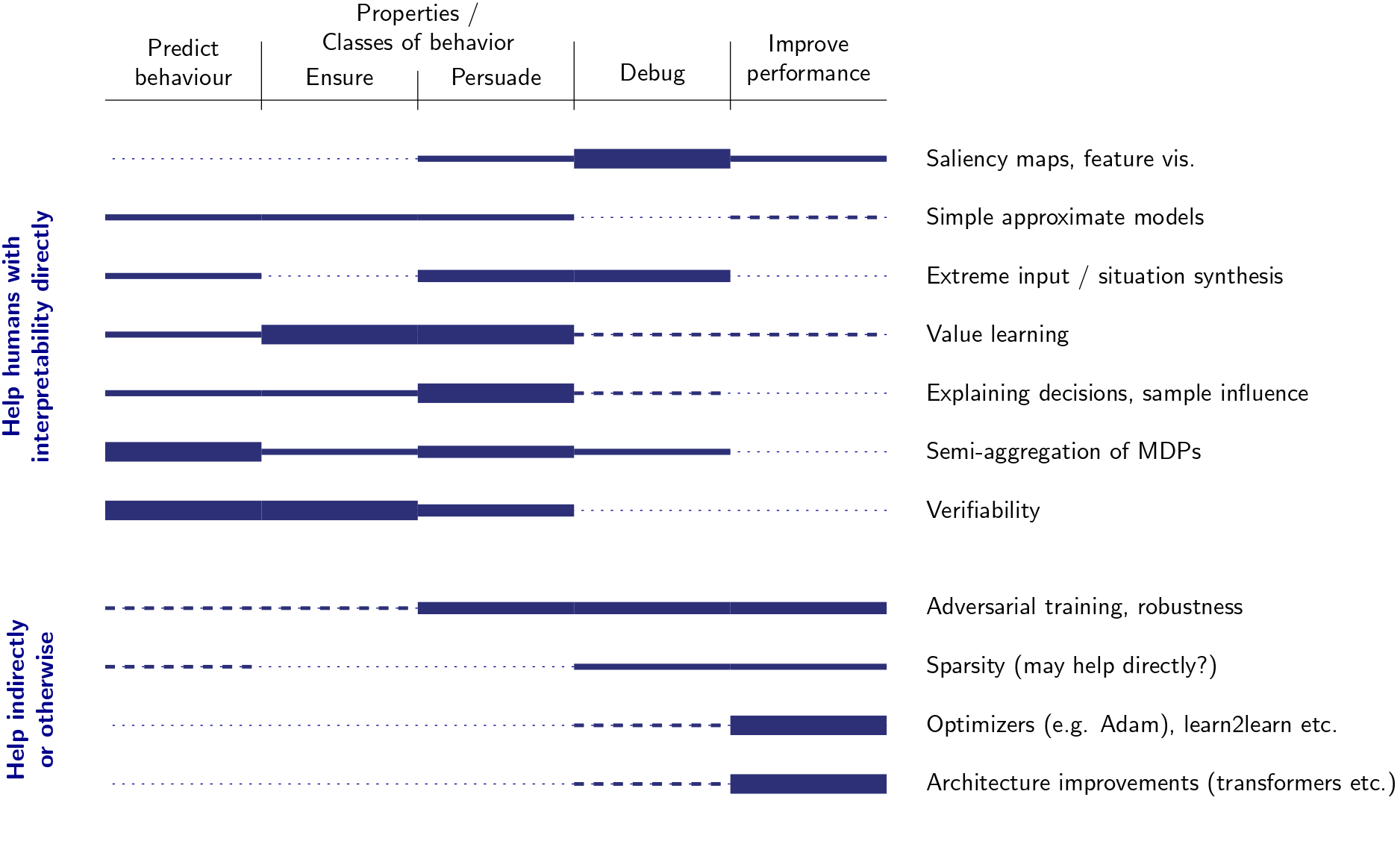
These dimensions aren’t an operationalisation of interpretability, and don’t present necessary and sufficient conditions, and we’re uncertain whether it’d be useful to have a strict dividing line. We do think that the framing is useful even if it’s not a formal definition of what interpretability is, as it helped us to discuss what goals interpretability methods are trying to achieve, and whether they’re enabling humans to achieve those goals or not. To test out our ideas with a variety of current methods, we produced a map of current interpretability methods on these two dimensions. This helped us in earlier formulations to spot problems with the description of the framing, relations between various parts of it, and similar patterns of goal behaviour from different methods. This is just an illustration of applying some of our ideas to current methods. Bold lines indicate that method helping more with that goal. We don’t want to stake a lot on exactly where the bold lines are drawn.
Other dimensions
The two dimensions described above were the ones we felt were the most useful at a higher level when thinking about generating ideas for interpretability methods. However, there’s a few other dimensions which we think are also important to think about. This can also be useful in a generative sense. If we draw out the matrix of all dimensions, we can consider whether methods in certain points of the matrix would be useful, and how they might look. These other important dimensions are:
- Interpreting the training process vs finished model (vs both). A method might aim to interpret how training happens (such as LCA: Loss Change Allocation for Neural Network Training or Understanding Black-box Predictions via Influence Functions), or it might be interpreting the finished model (such as Feature Visualization).
- We think this dimension can still be orthogonal to the Goals dimension, as we might want Assurances of properties or Predicting Behaviour of the training process as opposed to the finished model. The distinction is more blurry when it comes to Improving model performance or Debugging models, but we can still say a method looks at the training process of the finished model (or both) to aid in achieving this goal. In an online/meta-learning setup this also not be a crisp definition, as these paradigms have training as part of the “finished model”.
- Level of access to components of training and model. In some settings, we might have access to all the training data, the whole training process (i.e. the mini batches and loss and model checkpoints at every iteration), the final model (i.e. it’s architecture and weights), and a copy of the environment/simulation (especially relevant in reinforcement learning). In this full information setting many more interpretability methods are possible than in a setting where we only have access to the final model (architecture and weights), or even just examples of it’s behaviour.
- We find it useful to think about what resources the interpretability method requires to produce its results. This is especially pertinent in reinforcement learning, as some methods such as in Understanding DQNs require running the model for many time steps in the environment to gain insight from a behavioural standpoint, but this can be problematic depending on the type and simulatability of the environment.
- Ground Truth Access. Some interpretability methods may rely on access to the ground truth, either from a human’s evaluation or otherwise. In some settings (such as natural image classification) this is the case, but in reinforcement learning we don’t know what the optimal policy in most settings is. This will become more pertinent as we get stronger AIs and they start to overtake humans on domains other than board games.
- Methods like NetDisect require dense pixel level labellings of images, an even stronger notion of ground truth than just class labels for inputs, and gradient-based saliency methods require the ground truth label to take the gradient with, whereas perturbation based saliency methods and methods such as feature visualisation have no such requirement.
What’s next?
While the ideas in this post helped us deconfuse and discuss interpretability research in general, we think an ideal use-case for the framing (which also motivates us) is talking about interpretability in AI alignment. This problem setting is different from those tackled in the standard machine learning literature: We’ll care about a subset of the goals described above, and the way in which a method enables humans will also deserve more scrutiny. A second post coming soon will focus on this issue, using the ideas in this post and other previous writing on the subject. To give an (obvious) sneak preview, Persuasion of Properties is a goal we would want to avoid explicitly optimising for when thinking about aligning strong AI.
Appendix: Previous Literature
There have been previous works addressing the problem of defining and discussing interpretability research. We here summarise two works which seemed to be the most discussed.
The Mythos of Model Interpretability tackles the problem that interpretability is an under-defined term. The author first presents five desiderata which cover most interpretability researchers’ motivations for doing interpretability research: Trust, Causality, Informativeness, Transferability, and Fair and ethical decision making. In many problems, the problem specification used to train the model (i.e. the loss function, which normally just optimises accuracy) does not capture all of the desired properties of the model (i.e. not discriminating different races, having an understanding of causality, being transferable to other similar problems). Hence, optimising to solve this problem specification will not produce these properties. In these cases, Interpretability can be used to validate that these extra properties hold. This point is made both in this paper and following one.
The paper describes a taxonomy of interpretability methods, with the top level topics of transparency and post-hoc interpretability:
- Transparency is about understanding what procedure the algorithm is implementing, and in its strongest form about being to simulate the algorithm yourself. This definition has problems when we consider superhuman AI, as a human presumably won’t be able to simulate the AI’s algorithm. (See One Way to Think About ML Transparency for an attempt to solve this specific problem by extending the definition from human-simulatable in practice to human-simulatable in theory without constant access to the model being simulated).
- Post-hoc Explanations refers to methods which aim to understand or explain why a machine learning model has made a certain decision, either through examples, visualisation or explicit textual explanation produced by the model itself.
Towards A Rigorous Science of Interpretable Machine Learning echoes the point made in the above paper that interpretability research is aimed at addressing the case where the loss function a model is optimised for doesn’t capture all of the desired properties of the trained model. To the list of possible use-cases or problem underspecification cases it adds having a Multi-objective trade-off or only having trained with a Proxy reward function. It provides a semi-formal description of the variety of ways in which interpretability methods or models can be validated, and the links between these methods and the desiderata or methods described above.
Some papers we haven’t looked into but also seem to tackle a similar topic:
- The Challenge of Crafting Intelligible Intelligence
- Techniques for Interpretable Machine Learning
- Explicability? Legibility? Predictability? Transparency? Privacy? Security? The Emerging Landscape of Interpretable Agent Behavior
- The What, the Why, and the How of Artificial Explanations in Automated Decision-Making
- Explaining Explanations: An Overview of Interpretability of Machine Learning
This work was done as part of the AISRP 2019 https://aisrp.org/